Correlation and Existence
One of the hardest concepts to explain to students is the operation of a query containing correlation. As we are aware, the SQL optimiser generally evaluates a subquery first and only once. The subquery is replaced by a set of values that are then used as a filter for the parent query.
A correlated sub-query operates differently in that it is re-evaluated for each row in the parent query. This usually entails a significant processing price, and often slows down the query noticeably.
Q:List
the name of the most recently released album for each group, along
with the name of the group 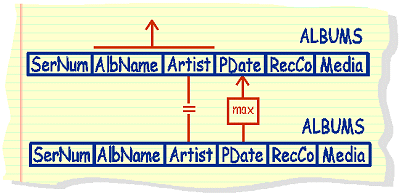 |
select
AlbName, Artist
|
In a diagram, a correlation is easy to spot as it usually entails BOTH a join and a sub-query between two or more tables. Students struggle, intially, with the encoding of such diagrams as they attempt to write a join query and then realise the sub-query does not fit once written.
Q:List
the name album and the group for all albums that have a track listing
recorded |
select
AlbName, Artist
|
The exists operator allows us to test for the presence of data yet seemingly breaks the rules governing allowable sub-queries. In the example above, the sub-query uses 'select *', which would normally result in an illegal 2 column sub-query answer table.
The sub-query does not actually retrieve any data, rather it tests to see if there is at least one row of data in the Tracks table that corresponds with the parent table, Albums. The backwards E is used for exists, and is consistent with it's other use as a not null indicator. Not Exists is similar, except the backwards E is crossed out (as in the not null example).
Many correlated queries can be re-expressed at non-correlated queries and this can vastly improve their execution time. The depth of a correlation (or the number of levels the correlation spans) can also effect the amount of re-calculation the query performs as well.