|
 |
|
||||||||||||||||
Tables contain RECORDS (or rows) of objects organised into columns called FIELDS. In the above example, the Performers table has 3 fields (SerNum, Artist and Instrument). Each field has a type also (common field types include, character, integer, real, ctring, date, currency, BLOB..). MySQL (the 'flavour of SQL we will start with) offers many field types, however we shall initially concentrate on two: TEXT =char(n) and NUMBERS =decimal(n). Eventually we will choose from a wider range of data types available - the field type is determined by the sort of information you are wanting to store there - numbers or not-numbers is usually the first distinction. Within numbers, there are lots of different styles of numbers (real, integer, date). Non-numbers also encompass various storage classes including text, file and so on. You can see a more complete set of data types in the MySQL Dictionary associated with this section. THE MUSIC DATABASE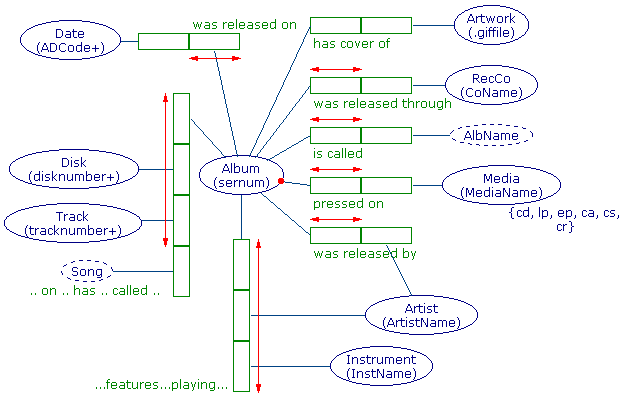
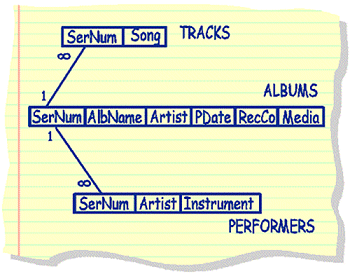
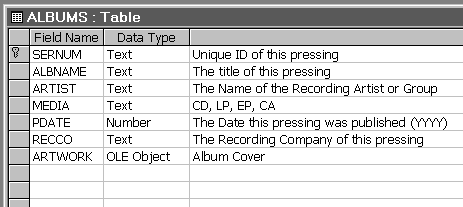
The MUSIC database comprises 3 related tables.... ALBUMS Table
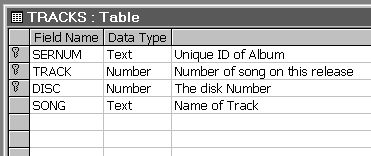
TRACKS
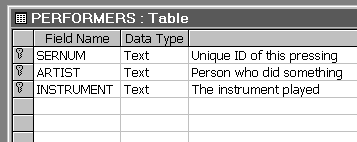
Table PERFORMERS
Table The above database will, through the course of instruction, become familiar to you as you investigate it's contents. It may appear strange to you that the data is stored in tables of this shape - DON'T PANIC, there is a GOOD reason for the shape of the table containers - this is covered elsewhere in the course. SQL is DECLARITIVE in nature - you tell it what to do, not how to go about doing it. It is termed a RELATIONAL LANGUAGE (as it conforms to the Relational Model of Data). Information stored using this type of language is called a RELATIONAL DATABASE, the controlling software is termed the RELATIONAL DATABASE MANAGEMENT SYSTEM (RDMS) The Relational Model Of Data - Some Important Starting DefinitionsThroughout this section, aspects of the relational model of data will be explained. Presented here are a selection of characteristic properties that typify data in a relational database. It is understood that:
example 1: a fragment of bit-mapped graphics could be reduced to a series of pixel co-ordinates and their corresponding indexed colour:
x y color
---------------------------
53 287 1
99 115 3
4 16 1
: : :
example 2: A Simplified Family Tree 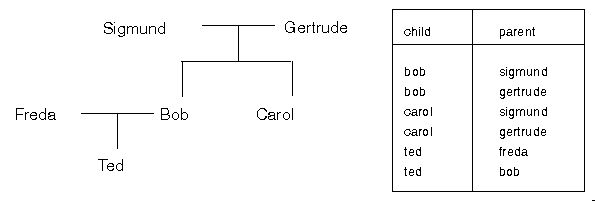
In both the above cases, the relationship between the entries in each of the rows are the SAME for each row, but NO ROW IS THE SAME AS ANY OTHER ROW Entries in each row RELATE to each other (eg. coordinates together define a pixel, or x is_parent_of_y) TABLES are collections of INSTANCES (tuples/rows/examples stored as records) of relationships. Each instance in a table has the same relationship type as other rows in that table, but a different one to rows in other tables in the system. Good table headings usually suggest what the relationships are. For example: in the Performers Table ser-num...features...artist...playing...instrument The table's instances (ie. rows/tuples in the table) form the tables' POPULATION. Providing the table with instances is called POPULATING the table. An un-populated table is termed a null table. It is not possible to populate the table with unrelated instances. As an example, it makes no sense to provide meteorological data in a table about births, deaths and marriages - regardless what the astrologers say :) TABLE ARITY - provides the degree of the relationship, or the number of objects involved in the relationship, or the number of columns on the table.
it is possible to have arity 1, with no instances - an empty (or null) UNARY table. Normalised TablesThe relational model of data requires that each FIELD (or column entry) is a SINGLE ENTITY (ie. no repeating groups). In other words, a column entry should be only a single piece of information. eg: ser_num songs
-------------------------------
NCC1701 song1, song2, song3
The above example is incorrect, as both the column heading (a plural) and inspection of the data reveal. This formation is not supported by the relational model of data, and therefore should we accept it as part of our table system, we would need to accept that some types of data retrieval requests (queries) are either impossible or very inefficient to complete. To re-work the same information into a relationally acceptable form, we could have: eg: ser_num song
-----------------
NCC1701 song1
NCC1701 song3
It should be noted that the two tables above 'say' essentially the same thing, the latter table, however, is easier or more straight-forward to access. Tables without repeating groups are termed FLAT(or normalised). Column entries should not be able to be divided (that is they should be SINGLE VALUED FACTS). IF this is not the case, search and retrieval problems arise through these repeating groups
eg mum dad children
------------------------------------
bob carol ted,alice,fred,olivia
This is really a repeating field also, as we have listed child objects together in a single field. "Who is the father of 'fred'?" requires a messy search using sub-strings and partial pattern matching (such a search becomes performance prohibitive on large databases) Row headings NOT ALLOWED - a relationally acceptable table has rows in which order is not important ! Repetition of rows is also not allowed
eg Mon Tue Wed Thur
1 IPT ENG MI CHEM
2 MII GR GEO IPT
3 FR RE ART YAK PLATTING
is a 'trivial' example where row headings (1,2,3...) allow the table to make sense - remove them and we lose information. The above information could be transformed into a number of relationally acceptable forms as detailed below: either day period class
mon 3 FR
wed 1 MI
or period mon tue wed thur
3 FR RE ART YAK
1 IPT ENG MI CHEM
Relational table design should never be dictated by the types of questions that are foreseen. The purpose to which the database is to be put is important, but if it is designed well, it can be used for many different things (with an increased liklihodd that it can cope with unforseen queries as well). Although these issues are important to performance of the database system, using them as the sole basis for design increases the liklihood that unplanned questions may not have answers in the resulting tables. Another common mis-conception is the difference between how the data is presented and how it is stored - these two aspects of the data may have little to do with each other. Inded, in a well designed system, the data may be displayed with great flexibility. It is (unfortunately) possible in poorly designed systems that certain questions have no easily attained answer. DON'T PANIC! ----> correctness of table design is covered elsewhere in the course. Tables that have been stored relationally in simple forms can be VIEWED differently - a VIEW is an alternative presentation of stored information, displayed prettily. Table KeysKeys are essential in a relational database. They are statements of UNIQUENESS. Keys are what is used by the RDMS to tell the rows of a table apart from each other, and how rows in one table relate to corresponding rows in another table. Unfortunately, terminology like Primary Key would tend to intimate that that type of key is more important than any other type of key - this is plain nonsense. All keys, be they 'primary', secondary, foreign or merely indexed fields are important.
The larger the
arity of the key, the more work the RDMS has to do to maintain the
integrity checking as data is added/modified. Large keys can seriously
impede system performance. In certain circumstances, an artificial
primary key (single column, like an ID) is created, to simplify the
indexing/updating of table rows. eg. Suppose we create a new music table 'Origins':
Artist Home
char(20) char(30)
key
3. SECONDARY KEYS
Key columns can be used to ensure that the database retains its integrity - that is the information is not allowed to be stored in an inconsistent form. Foreign key definitions enforce Referential integrity of the database. Be warned, however that they can cause CASCADE effects. Consider the effect of deleting an album - what effects would it have on the database??? Significant PopulationsA population is SIGNIFICANT if there are sufficient instances to deduce the PRIMARY KEY, and the underlying relationship binding the table together. |
|||||